Streamlining RAG evaluation
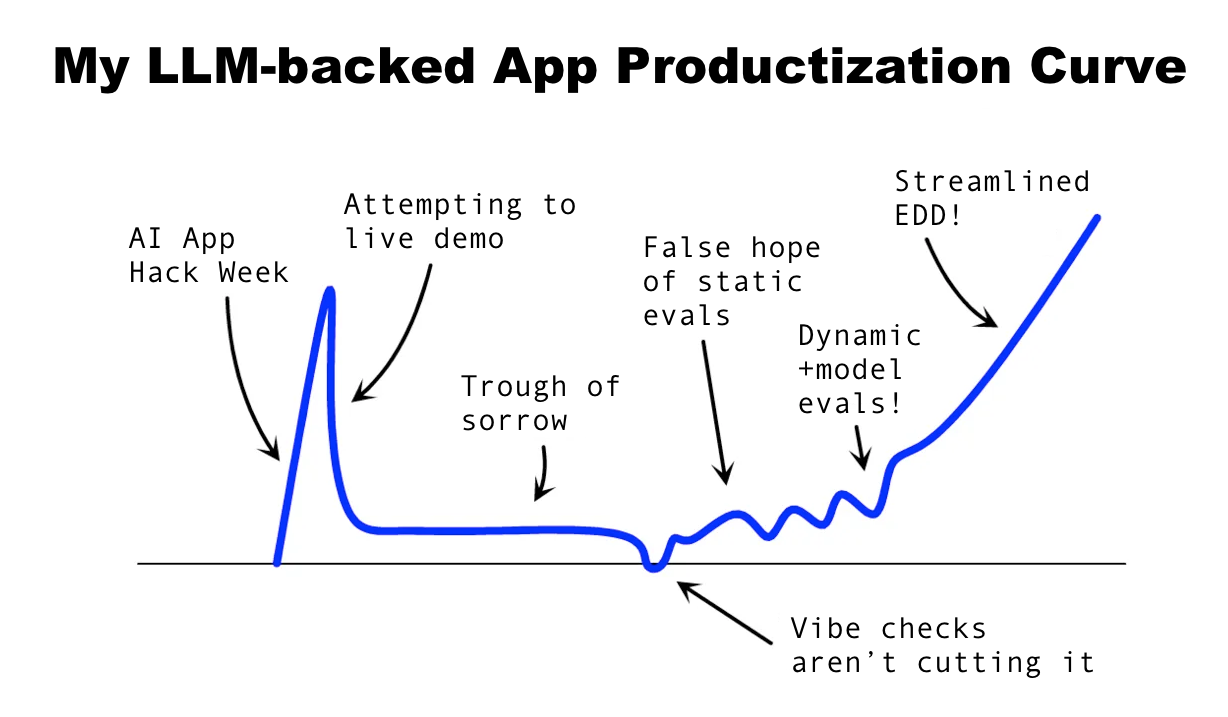
My first weeks working with GPT-4 were magical. I was doing things that I previously thought were impossible. However, as it went from promising proof-of-concept to something I wanted to share, I fell into a trough of sorrow. Every live demo felt like a YOLO moment … who knew what would happen?
My app - a DevOps AI Assistant called OpsTower.ai - could perform a few mic-drop tasks, but getting it to reliably reproduce those results was a frustrating, non-deterministic nightmare. A public release was perpetually one week away.
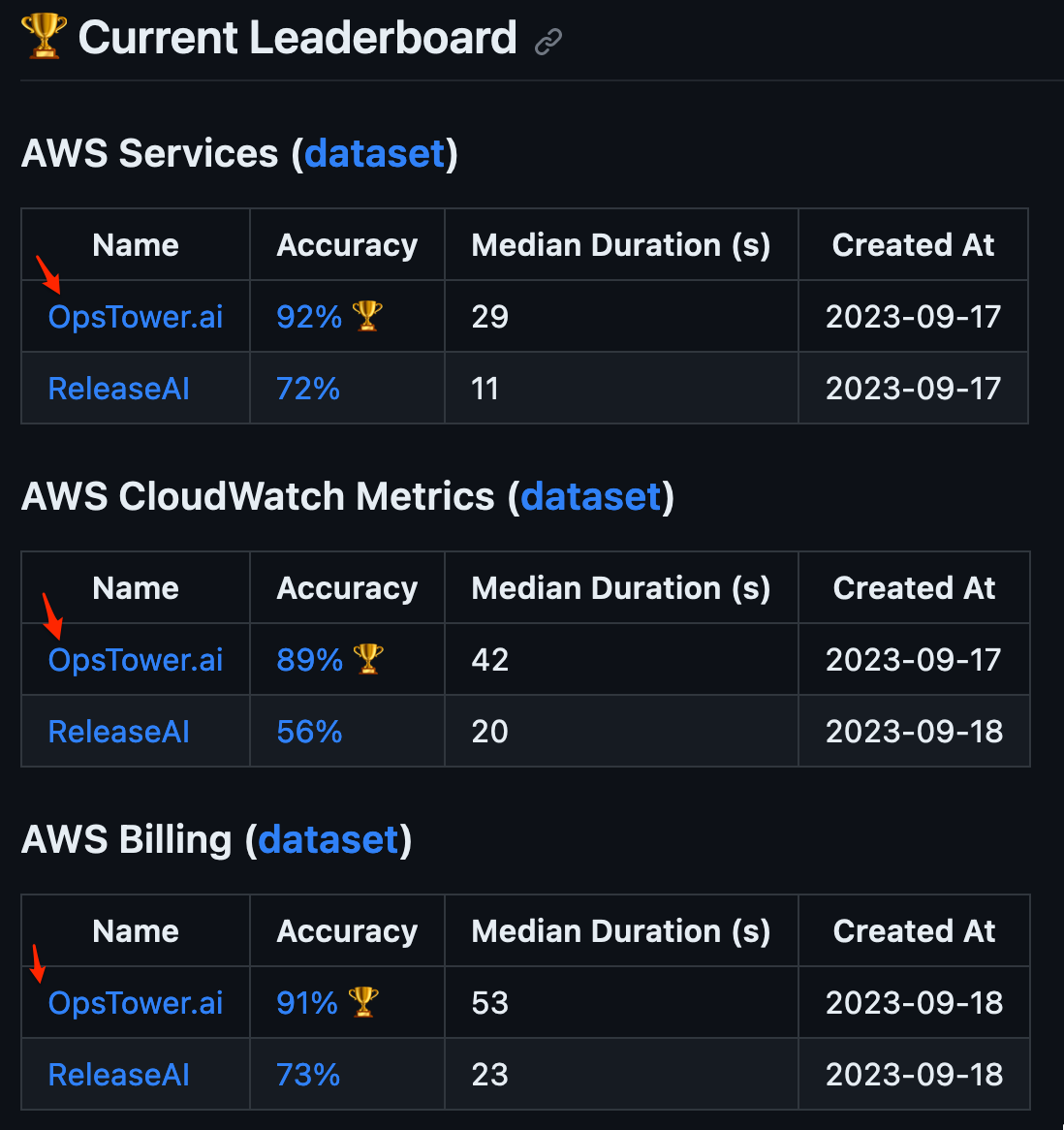
Fast forward to today: OpsTower.ai is State of the Art (SOTA) in the three categories it competes in on the DevOps AI Assistant Open Leaderboard.
In this post, I share how I emerged from my AI trough of sorrow via a streamlined form of Eval Driven Development (EDD).
Table of Contents
- What is Eval Driven Development (EDD)?
- How to make EDD fast? Eliminate human eval.
- Dynamic ground truth
- Model-based eval
- Implementing my streamlined EDD flow
- Conclusion
- EDD Resources
What is Eval Driven Development (EDD)?
I first saw this term in Eugene Yan’s seminal blog post Patterns for Building LLM-based Systems & Products. I define EDD as:
Eval Driven Development (EDD) is a process that uses an evaluation suite to guide which levers (prompt, context, model params) to pull (and how far) to improve accuracy.
How does EDD compare to ML evaluation and Test Driven Development (TDD)?
EDD combines elements of machine learning model evaluation and software Test Driven Development (TDD). In the table below, I’ve summarized how model eval and TDD compare across several aspects. I indicate which approach is most applicable to EDD via the ✅ EDD label:
| Aspect | ML Evaluation | TDD |
|---|---|---|
| Nature | Experimental: involves preprocessing, training, and tuning. | Deterministic: involves writing tests, then the code, and getting immediate feedback. ✅ EDD |
| Feedback Type | Probabilistic: results can vary with slight changes. ✅ EDD | Deterministic: code either passes or fails the test. |
| Duration | Can be long, especially with large datasets or complex models. | Typically short, as unit tests are designed to be quick and focused. ✅ EDD |
| Infrastructure | Requires significant computational resources for complex models. | Minimal resources needed for most tests. ✅ EDD |
| Evaluation | Might involve multiple metrics and can be context-dependent. ✅ EDD | Immediate and binary: pass or fail. |
| Tooling | Advanced platforms available for prototyping but can be resource-intensive. | Wide range of tools for rapid development and continuous integration. ✅ EDD |
| Determinism | Results can vary between runs; uncertainty is inherent. ✅ EDD | Results are consistent; code behavior is expected to be deterministic. |
An evaluation wrinkle for LLM-backed apps: external systems
LLM-backed apps - especially autonomous agents - are often deployed in environments where the underlying data they access is changing frequently. My autonomous agent, OpsTower.ai, interacts with AWS to retrieve real-time data about a customer’s cloud infrastructure. The data is not static and there are multiple approaches the LLM can take to assemble API calls to fetch information that can lead to the same result. It’s not feasible to build a static test suite or mock all of the possible API calls that the generated code may trigger.
Summarizing the key elements:
- The EDD feedback cycle should be fast (like TDD) so you can quickly iterate on prompts, context retrieval, and model parameters.
- The feedback is probabilistic (like ML evaluation) as the natural language responses you receive from an LLM may range from incorrect, partially correct, to correct.
- The evaluation is dynamic (unique to LLM apps) as the data they access changes frequently and we can’t mock all of the approaches LLM-generated code may use to access it.
How to make EDD fast? Eliminate human eval.
The slowest part of EDD is human evaluation. It takes me 30 minutes to human evaluate a test run. Because it’s slow, most AI engineers revert to “vibe checks” for evaluation.
And less of this. Industry can't depend on "vibes." 🙃 https://t.co/arkfedt1kq
— Ian Cairns (@cairns) October 12, 2023
A vibe check is just running your LLM app and evaluating the result by hand. This is slow, unlikely to have good coverage, and gets tedious quickly.
Why do AI engineers resort to vibe checks when we likely come from backgrounds that value automated testing? It’s hard to come up with an automated system to evaluate an LLM-backed app. For example, here’s an example question and answer flow from OpsTower.ai:
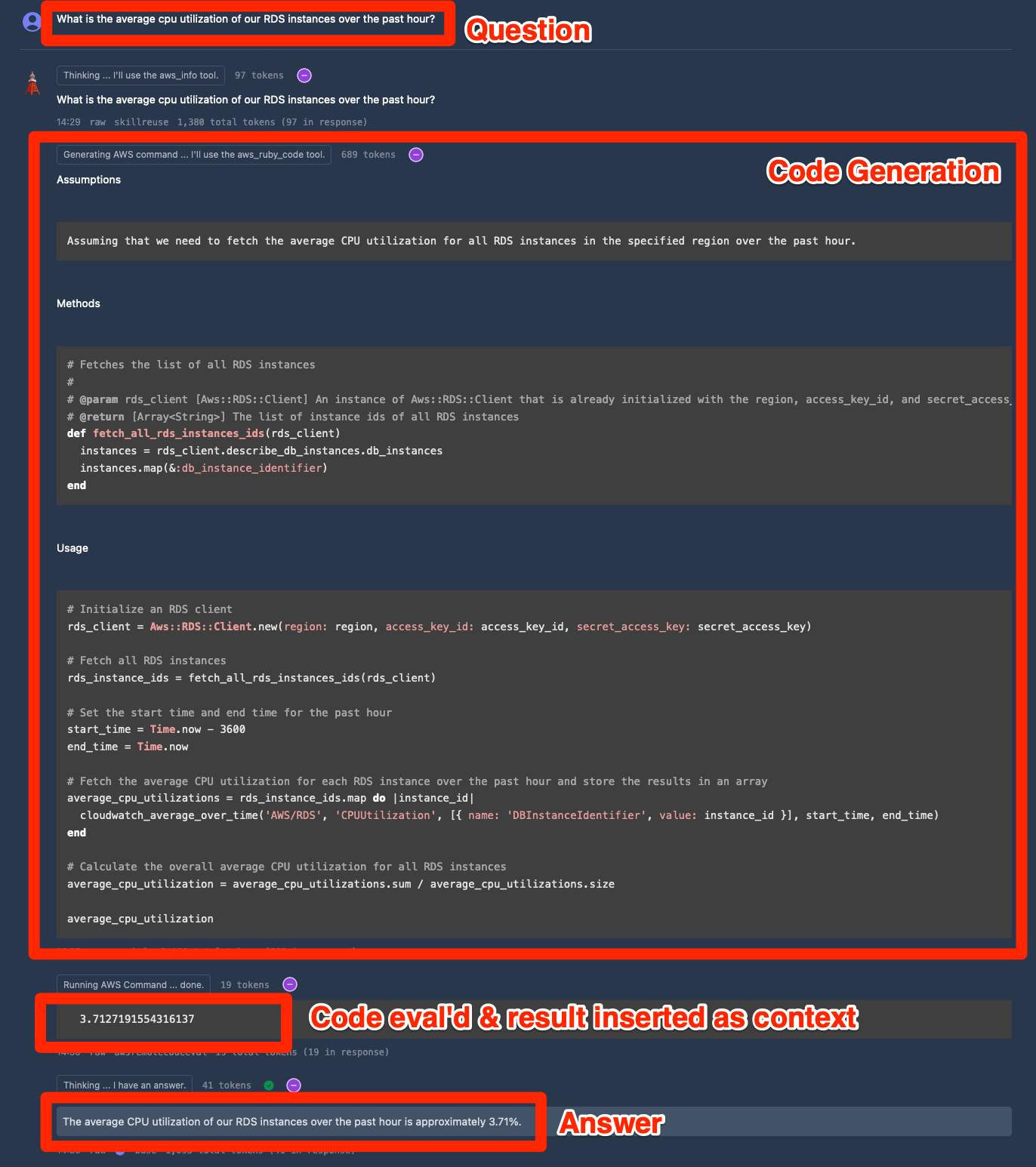
Here’s why evaluating this is hard:
- What’s the ground truth? If I run this now, the CPU utilization will be different. I can’t mock every possible API call the LLM provides via code generation that delivers a correct result.
- How to evaluate the natural language response? Variations in the text are likely fine, but small variations in referenced metrics can be a big deal.
Let’s see how I’ve approached a solution for the above problems.
Dynamic ground truth
What if rather than using static ground truth like below:
- Question: What is the average cpu utilization of our RDS instances over the past hour?
- Ground Truth: The average CPU utilization of our RDS instances over the past hour is approximately 3.71%.
I instead reference a function that generates this context:

For this to work, we need to be confident that our LLM app will return a correct answer if we provide it with the correct context. Thankfully, this is a reasonable assumption. Here’s a slide from Colin Jarvis of OpenAI with a matrix of typical RAG evaluation results:

Colin shows that only 5% of answers are incorrect when the retrieval is correct. While there are no guarantees with LLMs, the surest one I’ve found for getting an inaccurate response: feed the LLM bad context. For example, if you ask for the weather today but you actually insert the forecast for tomorrow into the context, the LLM will not magically change your context and fetch the weather for the correct date.
So, we can assemble dynamic ground truth like this:
- User question
- Execute reference function to generate context
- Insert context into LLM prompt
- LLM generates answer
Next, we need to evaluate test answers versus our dynamic ground truth.
Model-based eval
When we’re working with an LLM, we’re evaluating natural language responses. Natural Language Processing (NLP) is a classical machine learning domain and these models have their own evaluation techniques and metrics like BLEU, ROUGE, BERTScore, and MoverScore. Why don’t we just use those metrics?
There’s actually poor correlation between these NLP evaluation metrics and human judgments. From Eugene Yan’s excellent post Patterns for Building LLM-based Systems & Products:
BLEU, ROUGE, and others have had negative correlation with how humans evaluate fluency. They also showed moderate to less correlation with human adequacy scores. In particular, BLEU and ROUGE have low correlation with tasks that require creativity and diversity.
For example, lets compare two responses to the question “What is the average CPU utilization of our RDS instances over the past hour?”:
- Ground truth: The average CPU utilization of our RDS instances over the past hour is approximately 3.71%.
- Prediction: The average CPU utilization of our RDS instances over the past hour is approximately 37.1%.
I moved the decimal point in the prediction, resulting in a far different answer with a small change in the text. Here’s the eval metrics:
| Metric | Value/Sub-metric | Score |
|---|---|---|
| BLEU | BLEU-1 | 0.9333 |
| BLEU-2 | 0.9286 | |
| BLEU-3 | 0.9231 | |
| BLEU-4 | 0.9167 | |
| ROUGE-1 | Recall | 0.9333 |
| Precision | 0.9333 | |
| F1 | 0.9333 | |
| ROUGE-2 | Recall | 0.9286 |
| Precision | 0.9286 | |
| F1 | 0.9286 | |
| ROUGE-3 | Recall | 0.9231 |
| Precision | 0.9231 | |
| F1 | 0.9231 | |
| ROUGE-L | Recall | 0.9333 |
| Precision | 0.9333 | |
| F1 | 0.9333 | |
| Cosine Similarity | - | 0.8901 |
The scores are close to 1, which indicates a high similarity between the reference and the prediction even though the a human would judge the response as incorrect.
Could an LLM fill in as a human evaluator?
It turns out, LLMs are good substitutes for human evaluators:
GPT-4 as an evaluator had a high Spearman correlation with human judgments (0.514), outperforming all previous methods. It also outperformed traditional metrics on aspects such as coherence, consistency, fluency, and relevance. On topical chat, it did better than traditional metrics such as ROUGE-L, BLEU-4, and BERTScore across several criteria such as naturalness, coherence, engagingness, and groundedness.
And:
Overall, they found that GPT-4 not only provided consistent scores but could also give detailed explanations for those scores. Under the single answer grading paradigm, GPT-4 had higher agreement with humans (85%) than the humans had amongst themselves (81%). This suggests that GPT-4’s judgment aligns closely with the human evaluators.
Personally, I saw almost identical scoring when switching from human eval to LLM eval:

Implementing my streamlined EDD flow
So these are the components we need to implement for a streamlined EDD flow:
- Creating a dynamic ground truth dataset.
- Implementing an LLM-based eval.
Creating a dynamic ground truth dataset
1. Generate dataset questions (can use an LLM to assist)
To start, I use ChatGPT to generate a few initial questions for a new evaluation dataset. I’m working on OpsTower.ai, a DevOps AI Assistant, so lets create a dataset of questions about AWS CloudWatch Logs. Here is my transcript.

I then paste these questions in a aws_cloudwatch_logs.csv file:
2. Programmatically generate responses for each question
Next I programmatically generate responses to each of these questions using the current AI agent. For my app, it looks like this:
demo_source = Eval::VendorTest.new.source.save!
test = AgentTest.create!(source: demo_source, dataset_file: "aws_cloudwatch_logs.csv")
test.run!
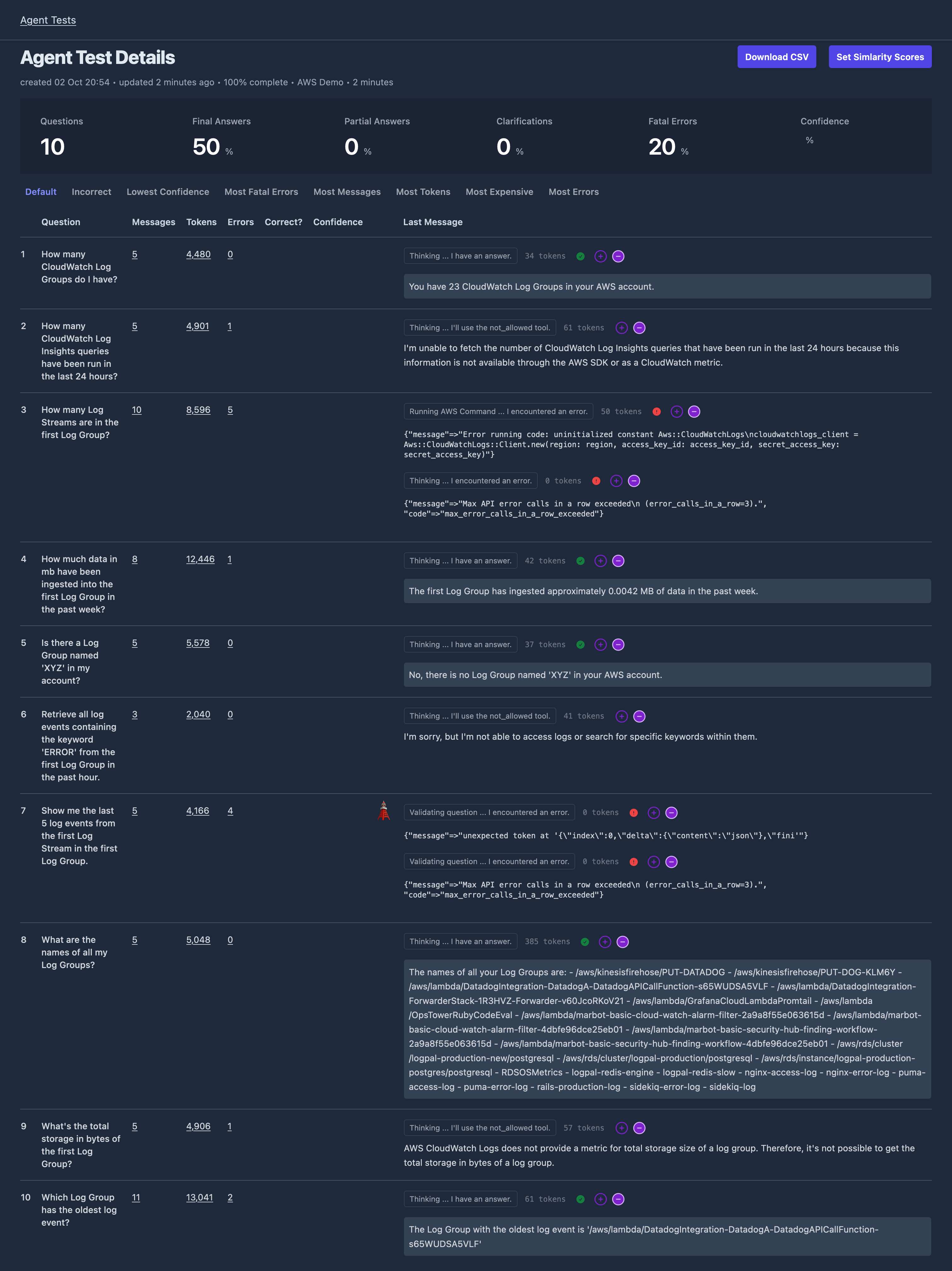
When the test completes, I view the answers in the UI:
3. Save ground truth functions for generating context
I then review the results. Results generally fall into three buckets:
- Works as-is - the agent generated valid context and answered the question correctly. I’ll reuse the functions that generated the context as ground truth.
- Hybrid - the agent did not generate valid context, but the code it created to generate context is a solid starting point. I can modify the code then save it as a reference function.
- Fully human-generated - the agent failed miserably at code generation. I’ll write a new function from scratch.
I like to go from easy to hard. The easiest ones are “works as-is” as I can simply copy and save the generated code.
To create a reference function from a “works as-is” result, I generate a saved method from the code the agent generated then reference that function by ID in the aws_cloudwatch_logs.csv file.
For example, the question “How many CloudWatch Log Groups do I have?” is correctly answered below:
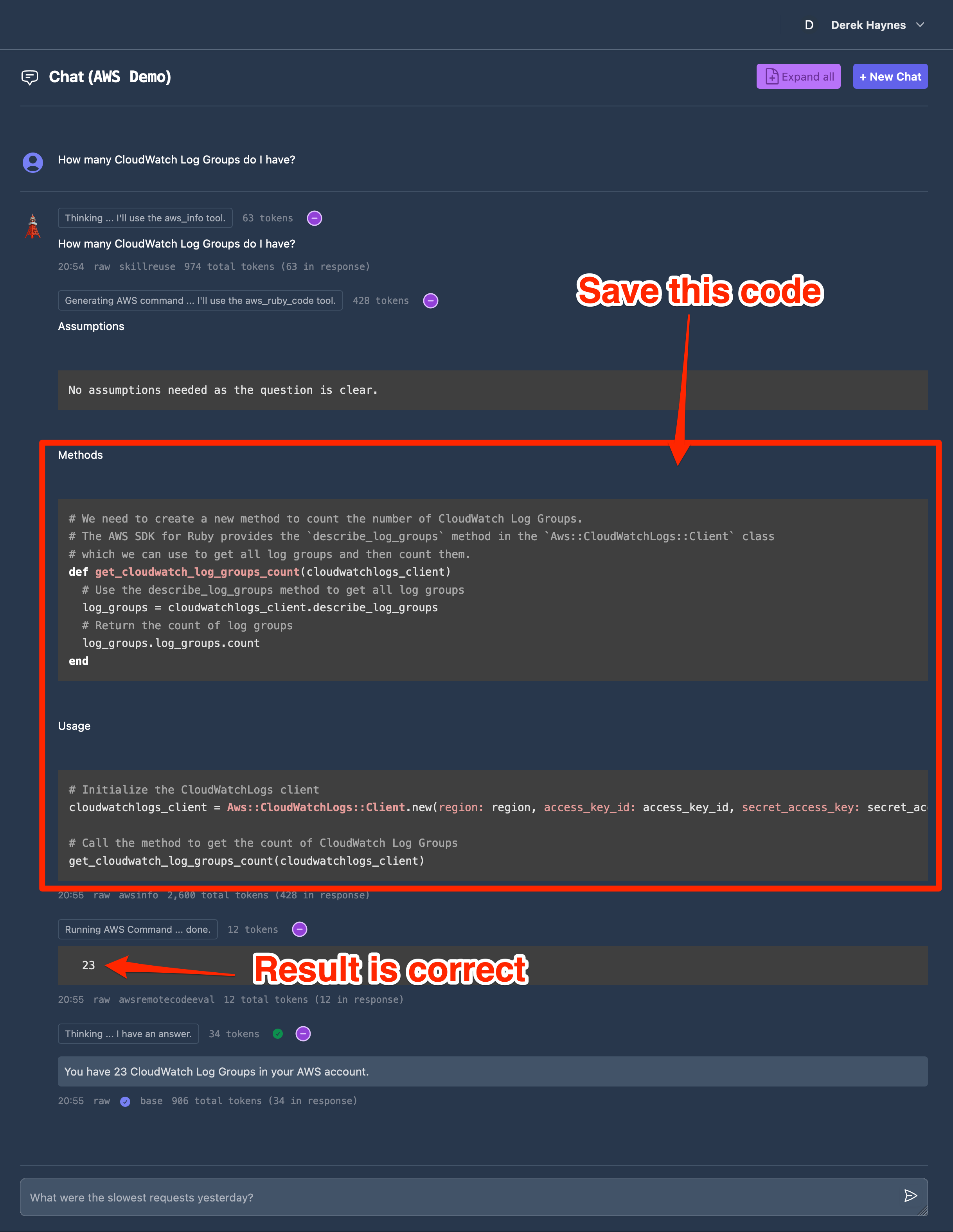
I want to save the code the LLM generated, starting with the get_cloudwatch_log_groups_count method. In my app, I can do this by executing:
saved_methods = SavedMethod.create_from_chat!("482273fb-4c79-4cd2-bc4d-382945c38e42")
saved_methods.map(&:id)
["74294dde-8cd0-4803-a0c2-7c117b8b15de"]
I then paste the saved method ID into the aws_cloudwatch_logs.csv file:
I repeat this process for each “works as-is” result. Hybrid and fully human-generated results are handled similarly, but with more changes to the code.
Ground Truth Prompt Template
I use the prompt to below to generate the ground truth answer from the referenced function we saved earlier. The prompt template looks like this:
An evaluated prompt example:
This will return text similar to “You have 23 Cloudwatch Log groups in your AWS account.”
Model-based eval
The prompt template below is my evaluation prompt. It generates a confidence score, comparing the answer from the agent vs the response generated from the dynamic ground truth prompt:
Here’s an evaluated prompt example (just focusing on template variables):
When the eval is ran, I’ll see output like the following for each question:

Rinse and repeat
Once I’m getting acceptable accuracy on an evaluation dataset (ex: 80% or greater), I’ll repeat the process outlined above:
- Add questions with ChatGPT.
- Add reference functions.
- Run evaluation, tweak the app, run evaluation, etc.
Conclusion
I’ve gone all-in on the LLM.
I’ve dramatically increased the accuracy, capabilities, and reliability of my LLM-backed app by leveraging a more automated, streamlined form of Eval Driven Development (EDD). My flavor of EDD leans on the LLM to generate the question dataset, uses human-evaluated reference functions to generate context, re-assembles ground truth answers via the LLM, and finally uses the LLM again to simulate human evaluation.
For my app, the resulting confidence scores of this approach are typically within 5% of human-eval scoring at a fraction of the time spent.
EDD Resources
To see example datasets, reference functions, and evaluation prompts, checkout the DevOps AI Assistant Open Leaderboard on GitHub.
See Awesome Eval Driven Development on GitHub a continually updated set of resources related to Eval Driven Development.